


سئو
آشنایی با گزارش crawl stats سرچ کنسول
2 تیر 1400
زمان مطالعه: 6 دقیقه

فهرست مطلب
آیا میدانید آخرین باری که بات گوگل به سایت شما request داده است کی بوده و با چه پاسخی مواجه شده است؟ کدام صفحه آخرین بار crawl شده است؟ اگر میخواهید پاسخ به این سؤال را بدانید باید به سراغ گزارش crawl stats سرچ کنسول بروید. در ادامه به معرفی این بخش مهم اما پنهان میپردازیم.
Crawl Stats چیست؟
این بخش که در قسمت Setting سرچ کنسول قرار دارد؛ اطلاعاتی درباره وضعیت سایت در مقابل درخواستهای ربات گوگل ارائه میدهد.
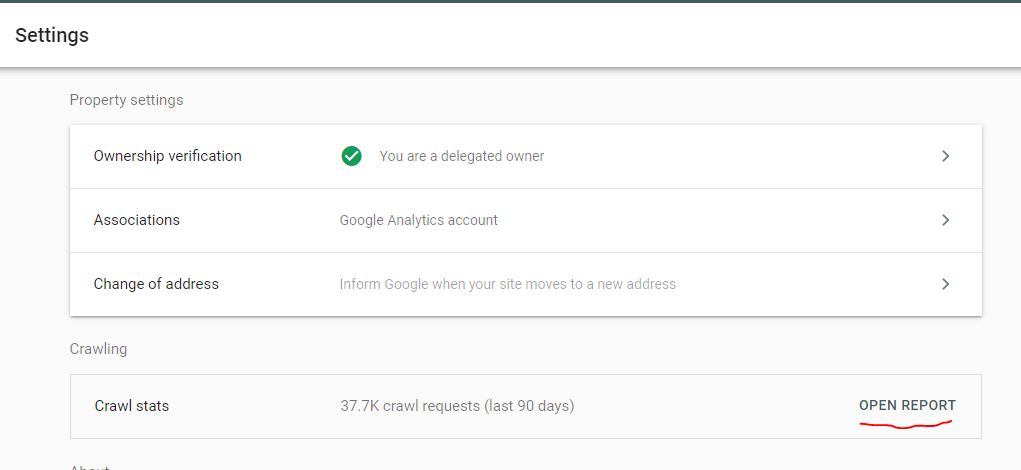
در این بخش دانستن چند نکته ضروری است:
- اگر در Property دامین اصلی هستید در گزارشها میتوانید گزارش مربوط به سابدامینها را هم مشاهده کنید؛ اما اگر در Property سابدامین هستید، گزارش URL های مربوط به سایر سابدامینها قابل نمایش نیست.
- اگر از منابعی مربوط به سایر دامینها در صفحات خود استفاده کردهاید گزارش خزش آنها را در این بخش مشاهده نخواهید کرد.
- این بخش گزارشهای http و https را شامل میشود؛ اما در قسمت URL های نمونه گزارش آن صفحاتی را مشاهده میکنید که عضوی از Property فعلی شما هستند؛ یعنی اگر در Property مربوط به http هستید؛ در قسمت مشاهده URLها موارد Http قابل مشاهده هستند.
- تمامی Request های مربوط به صفحات 301، 302 و 404 شمرده خواهند شد.
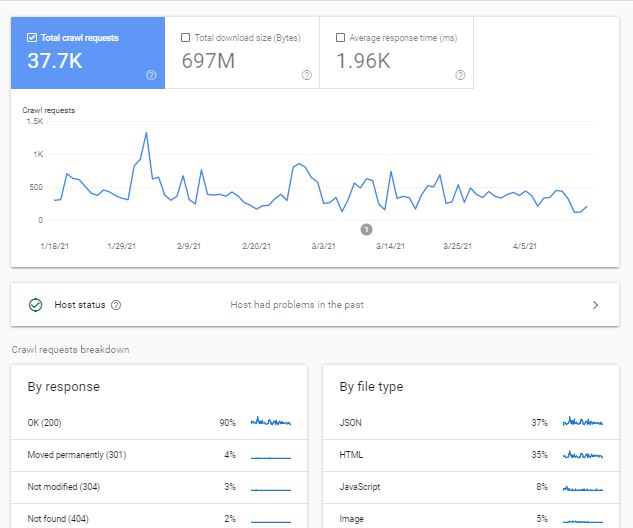
بخش Total crawl request
در این بخش نمودار مربوط به تعداد کل Requestهای بات گوگل نشان داده میشود که شامل Requestهایی با پاسخ موفق و ناموفق هستند. این بخش فقط منحصر به صفحات Html نیست و تعداد درخواستهای Crawl منابع صفحه مانند فایلهای CSS هم شمرده میشود.
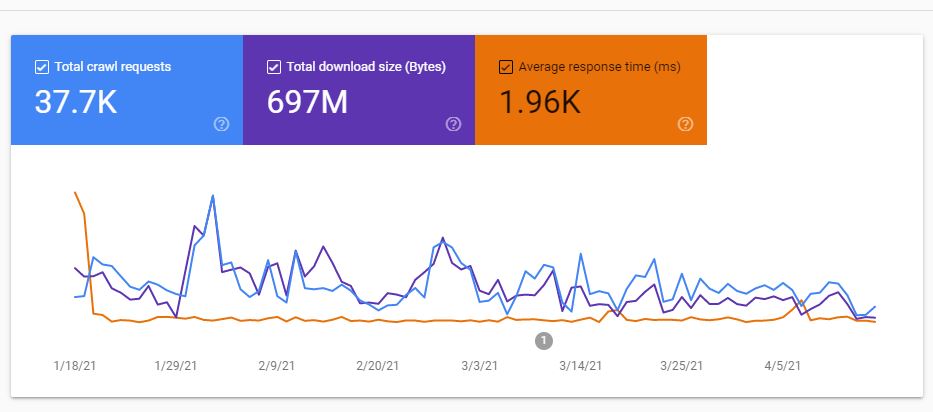
بخش Download size
حجم بایتهایی که با Crawl شدن صفحهها در هر روز دانلود میشود را نشان میدهد. اگر Cache برای منابع فعال باشد فقط در اولین مرتبه درخواست حجم آنها محاسبه میشود.
بخش Average Response Time
این نمودار مدت زمان میانگین (mSec) که به درخواستهای بات گوگل پاسخ داده شده را نشان میدهد.
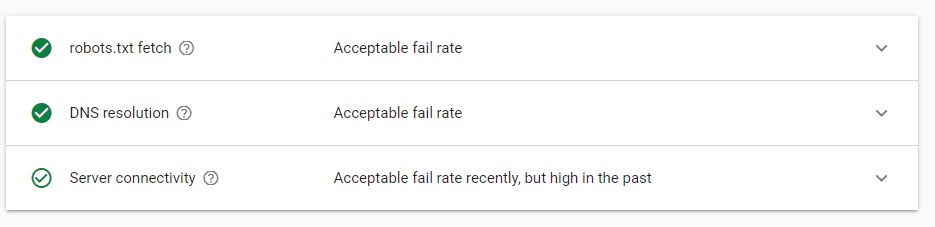
بخش Host Status
این بخش وضعیت پاسخدهی سرور شما را در برابر درخواستهای بات گوگل مشخص میکند. وضعیت پاسخ به سه شکل نمایش داده میشود:
- دایره سبز توپر: در 90 روز گذشته گوگل با مشکل قابل توجهی در هنگام درخواست به سایت شما مواجه نشده است.
- دایره سبز توخالی: حداقل یکبار در 90 روز گذشته گوگل در هنگام ارسال درخواست به سایت شما با مشکل مواجه شده است.
- دایره قرمز: در هفته گذشته حداقل یکبار سایت شما در دسترس نبوده است. این مورد حتماً بایستی مورد بررسی قرار گیرد.
جزئیات Host Status
همانگونه که در بند قبل اشاره شد؛ اگر دایره قرمز مشاهده شد حتماً باید بررسیهای لازم صورت پذیرد. این جزئیات در سه بخش با نمودار مجزا تقسیمبندی میشود:
مشکلات مرتبط با robot fetch
مشکلات مرتبط با DNS
در دسترس نبودن سرور (این مورد را حتماً به سرویس هاستینگ خود اعلام کنید)
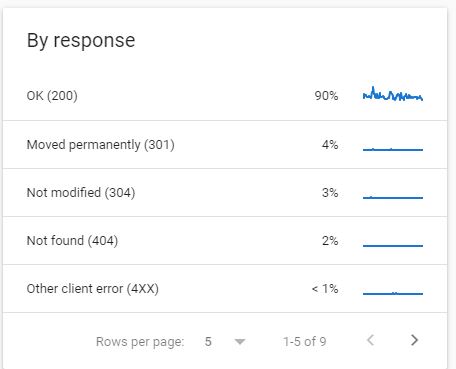
معرفی بخش By Response
در این بلوک انواع پاسخهایی که به درخواستهای Crawl داده شده است به نمایش گذاشته میشود. با کلیک کردن بر روی هر کد پاسخ، صفحاتی که این پاسخ را برگرداندهاند را میتوان مشاهده کرد.
- پاسخ 200: در حالت عادی بخش عمدهای از درخواستها پاسخ 200 را دریافت میکنند.
- پاسخ 301: در مواردی که صفحه خود را Redirect 301 کرده باشید این پاسخ را دریافت میکنید.
- پاسخ 302: صفحاتی که بهطور موقت Redirect شده باشند، پاسخ 302 را میدهند.
- پاسخ 304: اگر صفحه شما از زمان آخرین Crawl تغییری نکرده باشد، در مقابل آن پاسخ 304 ثبت میگردد.
پاسخهای 200، 301، 302 و 304 پاسخهای مناسبی هستند و میتوان در مواجهه با آن یک نفس راحت کشید.
- پاسخ Blocked by Robots.txt: این صفحات توسط فایل Robots.txt بستهشدهاند و ربات نمیتواند به آنها درخواستی ارسال کند. اگر صفحهای بهطور ناخواسته در این قسمت قرار دارد، این فایل را مجدداً بررسی کنید.
- پاسخ Not Found 404: برای صفحات 404 و لینکهای شکسته این پاسخ دریافت میشود. قطعاً هر سایتی ممکن است تعدادی صفحات 404 داشته باشد؛ اما برای اطمینان بیشتر این بخش را بررسی کنید تا لینکهای ناخواستهای در این بخش قرار نگیرد.
در ادامه به خطاهایی میپردازیم که حتماً باید بررسی گردد؛ چون بهتدریج از صفحات گوگل حذف میشوند:
- پاسخ Robots.txt not Available: اگر فایل Robots.txt شما برای مدتزمانی در دسترس نباشد، این پاسخ دریافت میشود. در این حالت گوگل درخواستهای Crawl را برای مدتی متوقف میکند (این پاسخ جدا از این است که فایل موجود نباشد.)
- پاسخ (Unauthorized (401/407: این دسته صفحات نیاز به لاگین کردن دارند. این پیجها را یا از طریق Robots.txt ببندید یا اگر از نگاه فنی نیاز به لاگین نیست، آنها را تغییر بدهید.
- پاسخ Server Error: حتماً این خطا را به تیم برنامهنویسی اطلاع دهید. این پاسخ مربوط به سرور و در برخی موارد ناشی از اشکالات ساختاری و یا برنامهنویسی است.
- پاسخ (Other Client Error (4XX: نوع این خطا مشخص نیست و باید علت آن طی بررسیهایی کشف گردد. بهعنوان مثال اگر در CDN شما IP های گوگل بسته باشد، صفحات با این خطا مواجه میشوند.
خطاهای دیگری مانند DNS Unresponsive، DNS Error، Fetch Error، Page Couldn’t be Reach، Page Time out، Redirect Error هم در دسته خطاهایی قرار میگیرند که باید بررسی شوند.
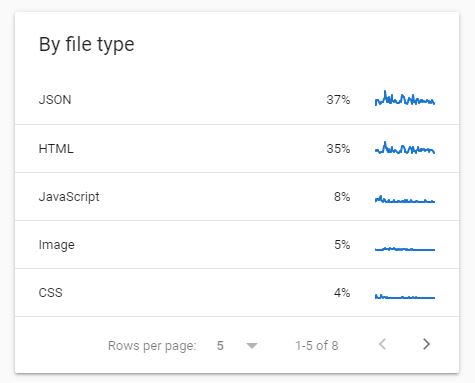
بلوک filetype
در این بلوک نوع فایلهایی که crawl شدهاند را به تفکیک درصد مشاهده میکنید. نوع فایلهای نمایش داده شده عبارتاند از:
CSS
JavaScript
Video
Image
Html
Json
PDF
Audio
Syndication (اطلاعات RSS)
و…
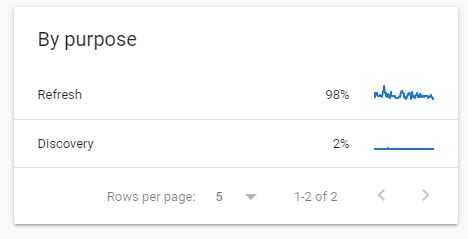
بلوک crawl purpose
این بلوک شامل دو بخش discovery و refresh است. URL هایی که برای اولین بار شناسایی و crawl میشوند در بخش refresh جای گرفته و URLهایی که قبلاً crawl شدهاند در بخش refresh قرار میگیرند.
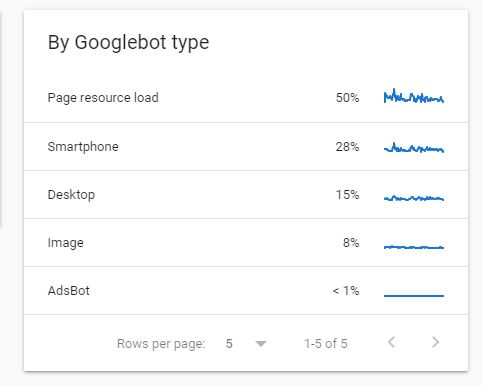
بلوک google bot type
همانطور که میدانید گوگل برای اهداف مختلف از باتهای مختلفی استفاده میکند که هرکدام رفتار مختص به خود را دارند. بات های این بخش عبارتاند از:
Smartphone
Desktop
Image
Video
Page resource load (برای منابع صفحه مانند CSS)
Adsbot (برای تبلیغات گوگل)
Storebot
Other agent type
با کلیک کردن بر روی هر بات می توان صفحاتی که توسط این بات بررسی شده و نوع پاسخی که دریافت کرده است را به تفکیک مشاهده کرد.
چند نکته درباره بررسی نرخ خزش
- در صورت اضافه کردن بخش جدید به سایت، نرخ خزش شما جهش پیدا خواهد کرد.
- اگر سرعت پاسخ به requestهای گوگل از سمت سرور شما کند باشد، به تدریج بات تعداد درخواستهای خود را کاهش میدهد تا فشاری به سرور وارد نشده و بتواند به درخواست کاربران پاسخ هد.
- در ابتدای افتتاح سایت و ساخت صفحات جدید عمده درخواستها از جنس discovery است و به تدریج به refresh تبدیل میشود
- صفحاتی که مدت زیادی محتوای آنها به روز نشود معمولاً کندتر crawl میشوند.
هر سایت یک بودجه crawl مشخصی دارد!
در هر بازه زمانی (مثلاً یک روز) به تعداد صفحاتی که توسط باتها crawl میشوند بودجه (crawl budget) میگویند. این بودجه به منابع سرور شما، محبوبیت صفحه و لینکهای ورودی به آن، تازگی محتوا و نوع صفحه بستگی دارد. یکی از برنامههای متخصصین سئو در تحلیل یک سایت، بررسی crawl budget و بهبود آن است که در مطالب آتی به آن خواهیم پرداخت.


نوشین دهقان
من یک فعال در زمینه سئو هستم. چیزهایی رو بهتون میگم که تو این مدت تجربه کردم و یا از اساتید یاد گرفته ام.



مطالب پیشنهادی





پیپل از هویت بصری جدید خود رونمایی کرد
هادی مرادی

راهکار جدید ادتریس: یکپارچگی ایونتها در ادتریس و گوگل ادز
تحریریه دیامبرد

برای ارسال نظر باید وارد شویدlogged in
در بخش بلوک crawl purpose یک اشتباه تایپی وجود داره برای هر دو مدل از url ها را در دسته refresh قرار دادید.
ممنون . مطلب مفیدی بود .بیشتر توضیح دهید لطفا (این پیجها را یا از طریق Robots.txt ببندید یا اگر از نگاه فنی نیاز به لاگین نیست، آنها را تغییر بدهید.)
با سلام
مطلب خوبی بود استفاده کردم . تشکر
میتونست کمی عکیق تر و تحلیلی تر هم باشه
سلام. خیلی ممنون از شما
بله حتما در آینده بخش های تحلیلی تر به این مطلب اضافه خواهدشد